Introduction
Recent developments in code completion and generation have been significant. Over the past several years, the field has progressed from generating relatively simple programs to solving real-world issues within software repositories. However, most studies in this area are based on static snapshots of code, with only a small body of research exploring the potential of leveraging dynamic code properties, such as runtime information and memory state, for code generation.
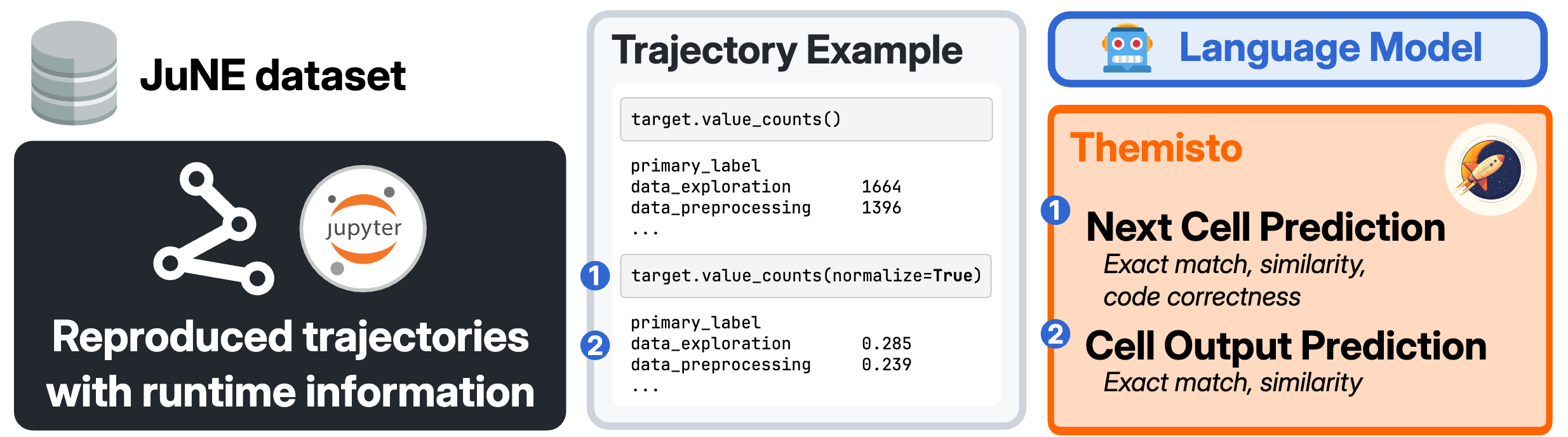
Jupyter notebooks offer a unique opportunity in this regard—they enable code generation while providing access to runtime information and the current state of the environment. In this paper, we present a benchmark designed to measure how models can utilize runtime and environment information, using development trajectories of Jupyter notebooks.
A development trajectory is a sequence of Jupyter notebook cell executions in the order performed by a human developer. Each operation includes the cell's content and the runtime state after execution. We propose evaluating a model's ability to predict the code of the next cell to be executed and the output of a given executed cell.
Data & Tasks
Our benchmark consists of a set of Jupyter notebook development trajectories. Each development trajectory consists of all prior cell executions with the given cell's execution context (e.g., cell content or runtime snapshot). The order of executions was recorded from the notebook development process and is preserved in our benchmark.
We have selected two tasks for evaluation:
- Next cell prediction: In this task, we ask the model to predict the code of the next cell to be executed in our trajectory. This task offers an interesting perspective on code generation, as it requires a significant understanding of the given trajectory to determine what needs to be done next.
- Cell output prediction: In this task, we ask the model to predict the output text for the cells with such output type. This task can be challenging for language models in a default snapshot setup, as it requires a strong understanding of the code and effective modeling of the runtime behavior.
To measure performance on these tasks, we use the exact match, ROUGE-L, and ChrF metrics.

Dataset
To acquire the trajectories, we used the JuNE dataset, where the authors tracked the notebook development process for over 8 hours with a small number of participants. They collected more than 14,000 user events, including more than 9,000 cell executions during these experiments across 29 notebooks for two original tasks.
To develop our benchmark, we replicated the environment and re-executed four notebooks from the dataset, resulting in a total of 1,453 code executions. Moreover, we collected additional information, such as memory load and execution time of the cell. We also collected and serialized the state of the environment for each step to incorporate it into trajectories.
The trajectory features include:
- kernel_id: Unique identifier for the execution kernel
- code: Code executed in the cell
- output: Output produced by the executed code
- execution_time: Time taken to execute the code in seconds
- memory_bytes: Memory usage during execution in bytes
- runtime_variables: Dictionary of runtime variables in the execution environment
- hash_index: Unique hash representing the execution state
Results
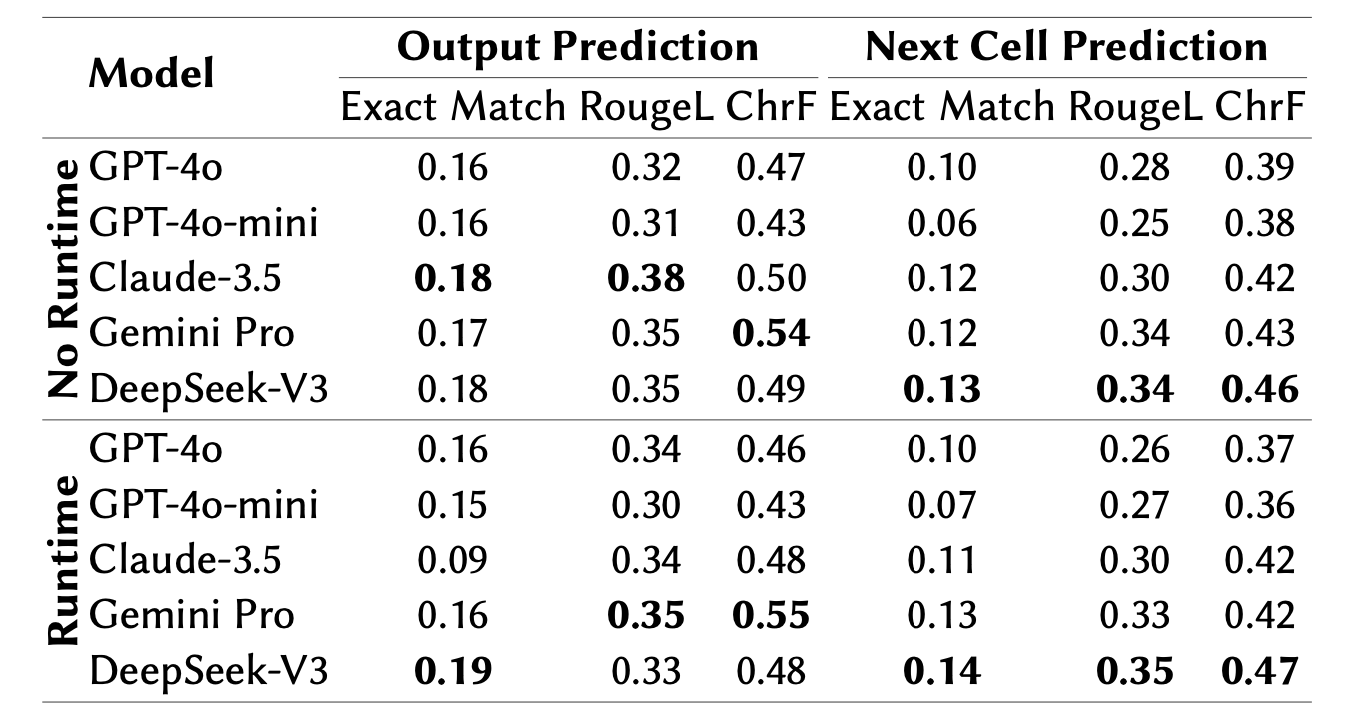
To provide an initial baseline for the benchmark, we selected a set of popular language models: GPT-4o, GPT-4o-mini, Claude 3.5 Sonnet, Gemini 1.5 Pro, and DeepSeek-V3. We report the benchmark in two settings: using runtime information during inference and without using it.
All tested models were able to produce a significant number of exact matches for the output prediction task without leveraging the runtime information. The best results were given by Claude-3.5, with 18% of cases achieving an exact match. All other models achieved very similar results, even though the set of correctly predicted examples differs from model to model.
The results for next cell prediction show poor overall performance across different types of models, particularly from the perspective of exact match. The best results are produced by DeepSeek-V3, achieving an exact match in 13% of cases. Similarly to output prediction, these results are compensated by higher scores on ROUGE-L and ChrF, indicating that the models at least produce outputs relevant to the next cell prediction.
After runtime inclusion experiments for code predictions, we found that the performance cannot be improved by simply adding all available information in the context and needs to be carefully curated. Although this information is surely valuable for accurate prediction and understanding of the current program state, the actual implementation is an interesting question for the research community.
Conclusion
With this benchmark, we introduce a new dynamic modality for code generation and program analysis, moving beyond static code base snapshots to incorporate complete development trajectories. This approach makes runtime information and development progress available to models, potentially allowing them to better align with developers' workflows and expectations.
Our findings demonstrate that this is a challenging problem that remains difficult even for advanced foundation models, opening new horizons for future research in areas such as runtime-aware code completion, dynamic context understanding, and interactive development assistance.
BibTeX
@article{grotov2024themisto,
title={Themisto: Jupyter-Based Runtime Benchmark},
author={Grotov, Konstantin and Titov, Sergey},
journal={arXiv preprint},
year={2024}
}